
Seznam českých Google písem – making of
Postup, kterým jsou vybírána a určována písma s českou diakritikou z Google Fonts.
Seznam cca 250 českých písem pro použití na webu jsem pochopitelně nevytvářel ručně. Jak ale automaticky zjistit, jestli daný font umí znaky s háčky a čárkami. A jak to celé udělat?
Seznam všech fontů
V první řadě bylo třeba získat všechna Google písma. To jde snadno přes API.
<?php
$webfonts = json_decode(
file_get_contents("https://www.googleapis.com/webfonts/v1/webfonts?fields=items%2Ffamily&key=API klíč"),
true);Potom si je lze vypsat cyklem:
foreach ($webfonts["items"] as $pismo) {
$pismo["family"]; // název fontu
}Připojení písma
Každé písmo je možné připojit vložením CSS souboru, který se dále odkazuje na existující písma. Přišlo mi trochu nešetrné připojovat stovky CSS definic písem, které připojí další stovky fontů.
Zjistil jsem, že URL pro jeden CSS soubor (při oddělování | může být v jednom CSS více fontů) s písmy může mít bezpečně asi 1600 znaků, takže se takto požadavky rozdělují.
Zjištění českých znaků
Testování diakritiky probíhá tak, že se pro každé písmo vytvoří dva elementy:
- jeden má znaky s diakritikou
ěščřžýáéňóůú, - druhý stejné znaky bez diakritiky
escrzyaenouu
Potom se jim nastaví testované písmo a JavaScriptem se přepočítá offsetWidth (šířka výsledného elementu). Vychází se z toho, že v případě podpory diakritiky bude šířka stejná.
Některé znaky jako í, ť nebo ď se netestují, protože mají různé rozměry od svých bez-háčkových a bez-čárkových variant i v běžných písmech (např. Arial).
Nakonec proběhne vyfiltrování, kdy JS vyháže elementy, kde se offsetWidth nerovná. A výsledný HTML kód už tvoří finální seznam.
Občas to nefunguje
Ano, některá písma to určuje chybně. Nicméně úspěšnější automatický postup zatím neznám…
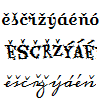




Komentáře