
Pročištění a opravení „prasáckého“ HTML
Jak z WYSIWYG editorů (jako třeba Word, starší TinyMCE/CKEditor) vytvořit rozumný a sémantický HTML kód.
Takový kód pro nadpis s odstavcem může vypadat následovně.
<p class=MsoNormal style='margin-bottom:12.0pt;line-height:normal'><b><span
style='font-size:14.0pt'>Nadpis</span></b></p>
<p class=MsoNormal style='margin-bottom:12.0pt;line-height:normal'><span
style='font-size:14.0pt'>Běžný text.</span></p>Tedy plno všelijakých stylů, ze kterých je cílem dostat něco jako:
<h1>Nadpis</h1>
<p>Běžný text.</p>Pro podobnou potřebu existují hotové nástroje, takže není potřeba vymýšlet nějaké komplikované regulární výrazy pro odstraňování nežádoucích atributů a podobně. (I když i to je možné.)
HTML Purifier
Jedná se o hodně kvalitní nástroj, který lze snadno široce konfigurovat (přesně si navolit, které značky a atributy mají projít, lze upravovat relativní a absolutní adresy), navíc zajišťuje 100% vyhovující HTML výstup (nehrozí neuzavřené nebo překřížené značky a podobně).
Hodně přísný zápis povolených značek a atributů může vypadat takto: p,b,a[href],i,br,img[src],ul,ol,li,table,tr,td
Příklad:
require_once 'HTMLPurifier/Bootstrap.php';
spl_autoload_register(array('HTMLPurifier_Bootstrap', 'autoload'));
$config = HTMLPurifier_Config::createDefault();
$config->set('HTML.Allowed', 'p,b,a[href],i,br,img[src],ul,ol,li,table,tr,td');
$config->set('AutoFormat.RemoveEmpty', true);
//$config->set('URI.Base', 'http://www.example.com');
//$config->set('URI.MakeAbsolute', true);
$purifier = new HTMLPurifier($config);
$clean_html = $purifier->purify($dirty_html);Texy!
Není to sice primární účel, ale tento nástroj jde použít i k opravě a kontrole nad HTML kódem. Nenabízí tak pohodlnou konfiguraci jako HTML Purifier, ale zase je tato knihovna datově menší a rychlejší.
Příklad:
require_once '/Texy/Texy.php';
$texy = new Texy();
$texy->setOutputMode(Texy::HTML5);
$texy->allowedTags =
array(
'p','b','i','br','ul','ol','li','table','tr','td',
'a' => array('href'),
'img' => array('src'),
);
$texy->allowed = array('html/tag' => true);
$clean_html = $texy->process($dirty_html);Nevýhody Texy! pramení z toho, že je určen primárně k něčemu jinému.
Hlavní rozdíl je v nevyhazování neznámých značek (atributy se vyhazují). Texy! je převede na entity, takže se budou v textu zobrazovat. U ukázky na začátku zase z podivných důvodů nechá element <span>.
Výhoda spočívá v poměrně zdařilých typografických úpravách, které Texy nabízí (pokud se zakomentuje $texy->allowed = array('html/tag' => true);).
Ruční úpravy
Takto se lze dobrat k slušnějšímu kódu.
<p><b>Nadpis</b></p>
<p>Běžný text.</p>A nezbývá než si vytvořit regulární výrazy, které kód vylepší do finální podoby.
Vytvoření nadpisu může být náhrada <p><b>(.*)</b></p> za <h1>$1</h1>.
Testovat, zda regulární výrazy fungují, lze pohodlně v editoru Sublime Text po stisknutí Ctr + H.
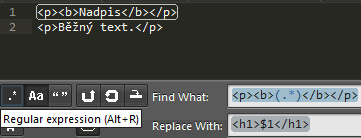
Poznámka: Někdy může být lepší provádět tyto ruční úpravy nad nepročištěným kódem.
Odstranění mezer
Hotová funkce odstraňující mezery z HTML kódu (bere ohled na blokové/inline značky a speciální elementy jako <pre>). Kromě toho uzavírá nepovinné značky a také uzavírá všechny hodnoty atributů do uvozovek.
Na co si dát pozor
Vstup od uživatele, je-li umožněno zadávat HTML, by vždy měl nějakým obdobným nástrojem být ošetřen; neošetření představuje bezpečnostní nebo jiné risiko. Mezi bezpečnostní patří např. vložení škodlivého skriptu, mezi jiná rozhození webu (třeba i neúmyslnou) chybou.
Co si myslíte o tomto článku?
Diskuse
Související články
Vlastní jednoduchý WYSIWYG editor
Chceme-li na webu zadávat text a běžná <textarea> už nestačí, řešením je napsat si vlastní WYSIWYG editor.

Souborový správce elFinder pro TinyMCE 4
Čtvrtá verse WYSIWYG editoru TinyMCE změnila API pro připojení správce souborů, co s tím?