
Parsování HTML v JavaScriptu
Jak v klientském i serverovém JS parsovat a upravovat HTML kód.
Pro parsování HTML kódu na straně klienta a získávání z něj nějakých informací je nejsnazší využít přímo DOM.
A cokoliv vybírat pomocí querySelectoru přes standardní CSS selektory:
const odkazyVTabulkach = document.querySelectorAll("table a");Je-li potřeba parsovat přímo HTML řetězec, jde použít DOMParser:
const parser = new DOMParser();
const doc = parser.parseFromString(`<p>Odstavec`, "text/html");
console.log(doc.querySelector("p").textContent)Zajímavější je to ale v JS na straně serveru, protože nemá document ani DOMParser a podobný pokus tak skončí chybou:
ReferenceError: document is not defined
ReferenceError: DOMParser is not definedRegulární výrazy
Stáhnout obsah jde metodou fetch a z výsledného textu půjde vyparsovat např. titulek stránky následovně:
const url = 'https://www.example.com';
fetch(url)
.then(response => response.text())
.then(html => {
const regex = /<title>(.*?)<\/title>/;
const match = regex.exec(html);
const title = match[1];
console.log(title);
})
.catch(error => console.log(error));Tímto celkem končí možnosti běžného parsování HTML bez externích knihoven.
HTML parsery v JS
Vzhledem k tomu, jak HTML funguje a jak fungují různé HTML značky, není úplně snadné si napsat vlastní parser.
Naštěstí existují hotové knihovny.
Ty fungují tak, že textový HTML vstup převedou do tzv. AST (abstract syntax tree), se kterým se dále pracuje.
Existuje hezký nástroj AST explorer, kde jde zkoumat jednotlivé parsery. A sledovat, jaký strom vytváří.

Mimochodem, ani ty hotové knihovny často nedokáží HTML pochopit stejně, jak funguje v prohlížeči.
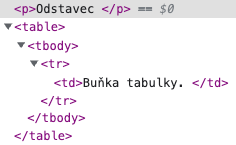
Například následující kód je naprosto v pořádku, je i validní, a prohlížeč před tabulkou odstavec ukončí.
<p>Odstavec
<table>
<tr>
<td>Buňka tabulky.
</table>A správně pochopí i konce řádku a buňky tabulky. Dokonce doplní i <tbody>:
Třeba populární parse5 si v tomto případě myslí, že HTML funguje jinak. Ukázka
Stejně se chová i nativní DOMParser v prohlížeč – ukázka.
Například jiný parser – htmlparser2 – si poradí i s touto konstrukcí. Ukázka
Hotová řešení
Nad těmito parsery existují potom další knihovny, které nabízí přívětivější rozhraní pro získávání obsahu nebo jeho modifikaci.
jsdom
Snaží se mít stejné rozhraní jako běžné DOM JS funkce v prohlížeči.
const dom = new JSDOM(`<!DOCTYPE html><p>Hello world</p>`);
console.log(dom.window.document.querySelector("p").textContent);Knihovna jsdom se hodně používá pro automatické testování JS kódu, protože kromě využití k parsování dokáže kód i spouštět atd.
cheerio
Implementuje styl zápisu ve stylu jQuery:
const cheerio = require('cheerio');
const $ = cheerio.load('<h2 class="title">Hello world</h2>');
$('h2.title').text('Hello there!');
$('h2').addClass('welcome');
$.html();
//=> <html><head></head><body><h2 class="title welcome">Hello there!</h2></body></html>Například přidat pomocí cheeria kotvy pro nadpisy 1–3 jde následovně:
const $ = cheerio.load(html);
$('h1, h2, h3').each((i, element) => {
const html = $.html(element);
$(element).replaceWith(`<a name="nadpis-${i}"></a>${html}`);
});
return $.html();Dokáže pro parsování používat parser5 i htmlparser2.
Deno DOM
Při používání Deno místo Node se nabízí použít tuto knihovnu. Zpřístupní běžné DOM metody na straně serveru ve stylu nativního DOMParseru.
import {
DOMParser,
Element,
} from "https://deno.land/x/deno_dom/deno-dom-wasm.ts";
const doc = new DOMParser().parseFromString(
`
<h1>Hello World!</h1>
<p>Hello from <a href="https://deno.land/">Deno!</a></p>
`,
"text/html",
)!;
const p = doc.querySelector("p")!;
console.log(p.textContent); // "Hello from Deno!"
console.log(p.childNodes[1].textContent); // "Deno!"
p.innerHTML = "DOM in <b>Deno</b> is pretty cool";
console.log(p.children[0].outerHTML); // "<b>Deno</b>"Himalaya
Převádí HTML do JSONu a zpátky:
import { parse } from 'himalaya'
console.log(parse(html))Pro následující kód:
<div class='post post-featured'>
<p>Himalaya parsed me...</p>
<!-- ...and I liked it. -->
</div>Výstupem je potom obyčejný JSON:
[{
type: 'element',
tagName: 'div',
attributes: [{
key: 'class',
value: 'post post-featured'
}],
children: [{
type: 'element',
tagName: 'p',
attributes: [],
children: [{
type: 'text',
content: 'Himalaya parsed me...'
}]
}, {
type: 'comment',
content: ' ...and I liked it. '
}]
}]S ním je možné provádět standardními JS metodami pro práci s objekty, co je potřeba. A výsledek klidně zase převést do HTML přes stringify.
import {parse, stringify} from 'himalaya'Hyntax
Další nástroj pro převod HTML do AST formátu bez dalších závislostí.
const { tokenize, constructTree } = require('hyntax')
const util = require('util')
const inputHTML = `
<html>
<body>
<input type="text" placeholder="Don't type">
<button>Don't press</button>
</body>
</html>
`
const { tokens } = tokenize(inputHTML)
const { ast } = constructTree(tokens)
console.log(JSON.stringify(tokens, null, 2))
console.log(util.inspect(ast, { showHidden: false, depth: null }))unified
Unified je universální rozhraní pro parsování čehokoliv. Existuje do něj spoustu pluginů.
Pro parsování HTML slouží rehype (existuje i třeba remark pro parsování Markdownu nebo retext pro obyčejný text).
Pro rehype něj spoustu pluginů, které řeší různé časté transformace HTML kódu.