Získání obsahu cizí stránky
Jak v PHP a JavaScriptu získat obsah z cizí webové stránky.
Získání obsahu
Chceme-li na vlastním webu pracovat s cizími daty, existuje k tomu v PHP hned několik způsobů.
Funkce file_get_contents
Použití je prosté:
$data = file_get_contents("http://jecas.cz/stazeni-stranky");V proměnné $data potom bude celý obsah stránky http://jecas.cz/stazeni-stranky.
Nevýhoda je, že řada hostingů tuto funkci pro stažení stránky z jiné domény blokuje. Jedná se o nastavení allow_url_fopen.
Funkce fsockopen
V případech, kdy file_get_contents není pro stahování z jiné domény k disposici, většinou funguje následující:
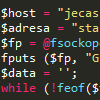
$host = "jecas.cz";
$adresa = "stazeni-stranky";
$fp = @fsockopen ($host, 80, $errno, $errstr, 10);
fputs ($fp, "GET /".$adresa." HTTP/1.0\r\nHost: ".$host."\r\n\r\n");
$data = '';
while (!feof($fp)) {
$data .= fgets($fp, 2048);
}
fclose ($fp);S rozdělením URL na $host a $adresa může pomoci funkce parse_url. V proměnné $data by opět měl být celý obsah stránky http://jecas.cz/stazeni-stranky.
Zpracování dat
Výše uvedeným způsobem získaný obsah je možné i rovnou vypsat (čehož je využito například v proxy skriptu).
echo $data;Nebo třeba přečíst obsah určitých HTML značek. K tomu se hodí regulární výrazy a funkce preg_match (popř. preg_match_all).
Nejjednoduší regulární výraz pro přečtení prvního nadpisu <h1> by mohl vypadat následovně:
$tagRegExp = '~<(h1).*>(.*?)</\\1>~iU';
preg_match($tagRegExp, $data, $matches);
$nadpis = $matches[2];V $matches[0] je celý nadpis včetně značek a v $matches[1] zase název značky, proto $matches[2].
Získání cizí stránky JavaScriptem
JS neumožňuje přímo stahování stránky z cizí domény, jediná možnost je vypomoci si výše uvedeným serverovým skriptem — ten stránku „stáhne“ na vlastní doménu a JavaScript se k němu potom může dostat prostým AJAXem, který v rámci domény funguje.
Nebo je možné použít JSONP.
Co si myslíte o tomto článku?
Diskuse
Související články

Generátor náhodných čísel online
Online generátor náhodných čísel z libovolného rozsahu. Náhodné číslo jedním kliknutím + kód pro JavaScript, PHP, Python a další jazyky.

JSON – formát a online nástroje
Co je JSON a jak s ním pracovat. Online formátovač, validátor a diff.

Výpis náhodného textu
Jak na stránce náhodně vypsat obrázek, odkaz, reklamu, text nebo cokoliv jiného.